Sending AWS RDS log files to S3 bucket
Using AWS RDS has added ease of database infrastructure setup and administration. Still as an Ops engineer you need to manage the database log files and archive them to storage. In this post I will discuss backing up RDS logfile to S3 bucket. This post is written not focusing on tight AWS security principles (such as not using AWS CLI key in EC2 instances) rather focused on general ideas to make the backup process succeed.
First we need to create an IAM group in AWS with RDS and S3 full access. Follow the screenshot below,
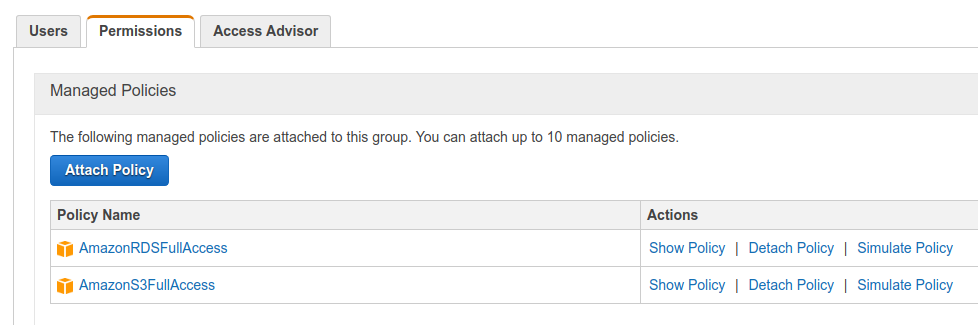 Create new IAM group
Create new IAM group
I am using AmazonRDSFullAccess and AmazonS3FullAccess policies. Although its not recommended to use S3 full access policy but I am trying to implement a basic general idea of backup process. Next create IAM user with AWS access key. We will be using this access key in aws CLI client (instead of using access credential in EC2 use IAM role while creating EC2 instance for better security). Next, install aws cli using pip and configure aws cli using aws configure command. Now it is time to use backup script for testing idea!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#!/bin/bash
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/home/ubuntu
INSTANCE='rds-db-identifier'
BUCKET='backup-db-log-bucket'
mkdir -p ${INSTANCE} && cd ${INSTANCE}
for i in `/home/ubuntu/.local/bin/aws rds describe-db-log-files --db-instance-identifier ${INSTANCE} --output text | awk '{print $3}' | sed '$d' | tail -n 10` ; do
FILE=`basename ${i}`
ARCHIVE=${FILE}.tar.gz
if [ ! -e ${ARCHIVE} ]; then
echo "Downloading ${i} ........."
`which aws` rds download-db-log-file-portion --db-instance-identifier ${INSTANCE} --log-file-name ${i} --starting-token 0 --output text > ${FILE}
tar -cvzf ${ARCHIVE} ${FILE}
echo "Uploading to S3 bucket ........"
`which aws` s3 mv ${ARCHIVE} s3://${BUCKET}/
rm ${FILE}
fi
done
Write this script to a specific location with the name backup. Next provide execute permission to the file using chmod u+x ./path-to-script for making the script to work. Make sure that you have provided authentic bucket name and db instance name. Now execute the script and you will see that rds logs from specific instance are getting downloaded in the local then getting archived and uploaded to S3 bucket with an end of file removal. You can use cronjob to automate the backup process after a fixed interval as following,
1
2
$ crontab -e
$ */45 * * * * /bin/bash /home/ubuntu/.crontasks/backup >/dev/null 2>&1
If you find this script buggy or want more feature then create an issue here
Comments